Table of Contents
ToggleDBSCAN -
Density Based Spatial Clustering of Applications with Noise :
Mastering unsupervised learning opens up a wide range of opportunities for data scientists. The vastness of unsupervised learning leaves a lot to be desired, but many newcomers to machine learning shy away from it. In fact, I believe most beginners stick to basic clustering algorithms such as k-means clustering and hierarchical clustering.
There is nothing wrong with this approach, but it limits your options when faced with a clustering project. And don’t limit yourself when you can expand your learning, knowledge, and skills by studying her powerful DBSCAN clustering algorithm.
Clustering is an essential machine learning technique, used in many fields and industries (think Uber’s route optimization, Amazon’s recommendation system, Netflix’s customer segmentation, etc.). This article is for anyone looking to add an invaluable algorithm to their budding machine learning skills: his DBSCAN clustering.
Why you need DBSCAN clustering ?
This is a affiliated question. Why waste time and energy learning a different clustering system when you formerly have a introductory clustering algorithm? This is a valid question, so let me answer it before explaining what DBSCAN clustering is.
Let‘s first clarify the part of clustering.
Clustering is an unsupervised literacy fashion that attempts to group data points grounded on certain characteristics. There are colorful clustering algorithms with K- Means and Hierarchical being the most habituated bones . Some of the use cases of clustering algorithms include
- Document Clustering
- Recommendation Engine
- Image Segmentation
- Market Segmentation
- Search Result Grouping
and - Anomaly Discovery.
All these problems use the conception of clustering to reach their end thing. thus, it’s pivotal to understand the conception of clustering. But then’s the issue with these two clustering algorithms.
Both K- means and hierarchical clustering fail to produce clusters of arbitrary shape. Clusters can not be formed grounded on different consistence. thus, DBSCAN clustering is needed.
Let‘s understand with an illustration. Then we’ve data points densely packed in the form of concentric circles.
Let’s try to understand it with an example. Here we have data points that are clustered together in the form of concentric circles.
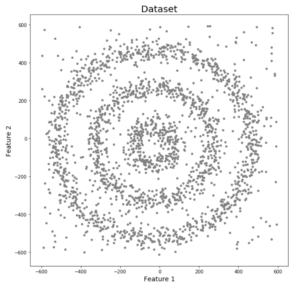
We see three different dense clusters in the form of concentric circles, which contain noise. Now let’s run K-Means and a hierarchical clustering algorithm to see how these data points are grouped.

You might be wondering why there are 4 colors in the chart. As I said earlier, this data also contains noise, so I picked up the noise as a separate cluster represented in purple. Unfortunately, neither could group the data points. It also failed to properly identify the noise present in the dataset. Now let’s look at the results of DBSCAN clustering.
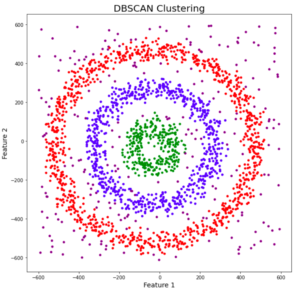
Great! DBSCAN not only can cluster the data points correctly, but it also perfectly detects noise in the data set.
What exactly is DBSCAN clustering?
DBSCAN stands for Density-Based Spatial Clustering of Applications with Noise.
Used by Martin Ester et al. DBSCAN is a density-based clustering algorithm, based on the assumption that clusters are dense regions in space separated by regions of low density.
“densely clustered” data points he groups into one cluster. By examining the local density of data points, you can identify clusters in large spatial datasets. The most interesting feature of DBSCAN clustering is its robustness to outliers.
Unlike K-means, where you have to tell the number of centroids, you also don’t have to tell the number of clusters up front.
DBSCAN only takes her two parameters, epsilon and minPoints. Epsilon is the radius of the circle that should be created around each data point to check density. minPoints is the minimum number of data points required within that circle to classify that data point as a core point.
In higher dimensions the circle becomes a hypersphere, epsilon is the radius of the hypersphere, and minPoints is the minimum number of data points required within the hypersphere.
It’s confusing, isn’t it? Let’s understand it with an example.

Here we have grayed out some data points. Let’s see how DBSCAN groups these data points.
DBSCAN creates a circle of epsilon radius around each data point and classifies them into core points, boundary points, and noise. A data point is a core point if the circle around it contains at least “minPoints” points. If the number of points is less than minPoints, it is classified as a boundary point, and if there are no other data points around the data point within the epsilon radius, it is treated as noise.
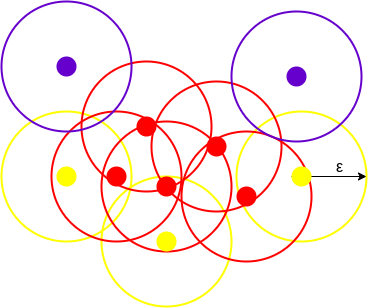
The figure above shows clusters created by DBCAN with minPoints=3. Here we draw circles of equal radius epsilon around each data point. These two parameters help create spatial clusters.
Any data point with at least 3 points within the circle, including itself, is considered a core point represented in red. All data points with less than 3 and more than 1 points within the circle, including itself, are considered boundary points.
They are represented in yellow. Finally, data points that have no other point inside the circle are considered noise and are colored purple.
To find data points in space, DBSCAN uses Euclidean distance, but other methods (such as great circle distance in geographic data) can be used. It also requires searching the entire dataset once, whereas other algorithms require multiple searches.
Reachability and Connectivity
These are two concepts that must be understood before proceeding. Reachability indicates whether a data point is directly or indirectly reachable from another data point, and connectivity indicates whether two data points belong to the same cluster. Regarding reachability and connectivity, DBSCAN’s two points can be referred to as:
- If X belongs to the neighborhood of Y i.e. dist(X, Y) <= epsilon
- Y is the core point
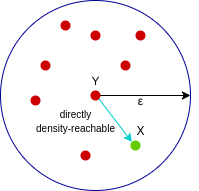
Here X is directly densely accessible from Y but The converse is not valid.
Point X has a chain of points p1, p2, p3, …, pn and p1=X and pn=Y, pi+1 reachable with direct density – pi.
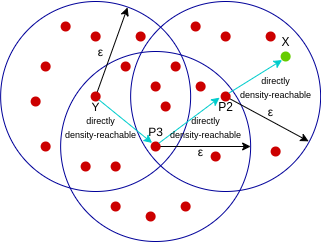
Here X is close to Y, X is directly close to P2, P2 is close to P3, and P3 is close to Y.
But the reverse of this is not valid.
A point X is density connected from a point Y with respect to epsilon and minPoints if there exists a point O and both X and Y are densely reachable from O with respect to epsilon and minPoints.
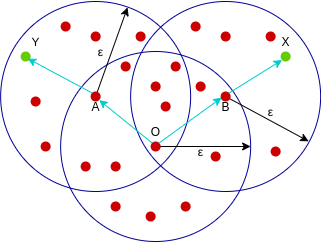
Here, since both X and Y are density-reachable from O, we say that X is density-connected from Y.
Parameter selection in DBSCAN clustering :
DBSCAN is very sensitive to the epsilon and minPoints values. Therefore, it is very important to understand how the epsilon and minPoints values are chosen. Small variations in these values can significantly change the results produced by the DBSCAN algorithm.
The minPoints value must be at least one greater than the number of dimensions of the dataset. H.
minPoints>=Dimensions+1.
It doesn’t make sense to assume minPoints to be 1. This makes each point a separate cluster. Therefore, it should be at least 3. Generally, it’s twice as big. But domain knowledge also determines its value.
Epsilon values can be determined from the K distance plot. The point of maximum curvature (elbow) in this figure tells us something about the value of epsilon. If the epsilon value chosen is too small, more clusters will be generated and more data points will be picked up as noise. Conversely, if the size chosen is too large, several small clusters will merge into his one large cluster, losing details.
